

Through our interactions with digital devices and systems us humans are now a diverse resource to other humans and machines. And we are changing in accordance with the processes and demands of contemporary, technological market systems, designed to extract as much data from us as possible. In his recent article Our minds can be hijacked, Paul Lewis of the Guardian revealed that those in the know, those who helped to create Google, Twitter and Facebook, are now disconnecting themselves from the Internet as, like millions of people in the world, they are feeling the effects of addiction to social networking platforms, and fear its wider consequences to society.
The hazards of this kind of tech-contagion have been the staple food of sci-fi for decades – a mysterious woman shares a strange but simple VR game in the 1991 episode of Next Generation Star Trek, The Game. It spreads like wildfire, taken up with enthusiasm by the crew, only later revealed to be a brainwashing tool invented by an alien captain to seize control of first the ship, and then all of Starfleet. Let’s look at ourselves for a moment – if we can tear our gaze away from our screens. How has our public behaviour changed – on the streets, on public transport, in buildings and parks? Our attention transfixed by our devices, online via our phones and tablets – bumping into each other, and even walking into the road endangering their own and others’ lives.

Professor of psychology Jean M. Twenge studies post-millennials and argues that a whole younger generation in the US, would rather stay in doors than going out and partying. Even though they are generally safer from material harm they are on the brink of a mass mental-health crisis. She says this dramatic shift in social behavior emerged at exactly the moment when the proportion of Americans who owned a smartphone surpassed 50 percent. Twenge has termed those born between 1995 and 2012, as generation iGen. With no memory of a time before the Internet, they grew up constantly using smartphones and having Instagram accounts. In her article Have Smartphones Destroyed a Generation? Twenge writes “Rates of teen depression and suicide have skyrocketed since 2011. It’s not an exaggeration to describe iGen as being on the brink of the worst mental-health crisis in decades. Much of this deterioration can be traced to their phones.”
Internet addiction is like having your head perpetually inside a magical mirror of hypnotically disembodying power #addictsnow pic.twitter.com/DFkl1jaKER
— furtherfield (@furtherfield) August 31, 2017
From the #addictsnow Twitter commission by Charlotte Webb and Conor Rigby, 2017
We offer three features as part of Furtherfield’s 2017 Autumn editorial theme of digital addiction, in parallel with the exhibition Are We All Addicts Now? at the Furtherfield Gallery, until 12th November 2017. Artist Katriona Beales has developed the exhibition and events programme in collaboration with artist-curator Fiona MacDonald: Feral Practice, clinical psychiatrist Dr Henrietta Bowden-Jones, and curator Vanessa Bartlett. She explores the seductive qualities, and the effects of our everyday digital experiences. Beales suggests that in succumbing to on-line behavioural norms we emerge as ‘perfect capitalist subjects’ informing new designs, driving endless circulation, and the monetisation of our every swipe, click and tap.
Firstly we present this interview with Katriona Beales* from the new book Digital Dependence (eds Vanessa Bartlett and Henrietta Bowden-Jones, 2017) in which she discusses her work and her research into the psychology of variable reward, “one of the most powerful tools that companies use to hook users… levels of dopamine surge when the brain is expecting a reward. Introducing variability multiplies the effect” and creates a frenzied hunting state of being.
Pioneer of networked performance art, Annie Abrahams, creates ‘situations’ on the Internet that “reveal messy and sloppy sides of human behaviour” in order to awaken us to the reality of our networked condition. In this interview, Abrahams reflects on the limits and potentials of art and human agency in the context of increased global automation.
Finally a delicious prose-poem-hex from artist and poet Francesca da Rimini (aka doll yoko, GashGirl, liquid_nation, Fury) who traces a timeline of network seduction, imaginative production and addictive spaces from early Muds and Moos.
“once upon a time . . .
or . . .
in the beginning . . .
the islands in the net were fewer, but people and platforms enough
for telepathy far-sight spooky entanglement
seduction of, and over, command line interfaces
it felt lawless
and moreish
“
And a final recommendation – The Glass Room, curated by Tactical Tech
Tactical Tech are in London until November 12 with The Glass Room, exhibition and events programme. A fake Apple Store at 69-71 Charing Cross Road, operates as a Trojan horse for radical art about the politics of data and offers an insight into the many ways in which we are seduced into surrendering our data. “At the Data Detox Bar, our trained Ingeniuses are on hand to reveal the intimate details of your current ‘data bloat’; who capitalises on it; and the simple steps to a lighter data count.”
*This interview is published with permission from the publishers of the book Digital Dependence edited by Vanessa Bartlett and Henrietta Bowden-Jones, available to purchase from the LUP website here.
“AI just 3D printed a brand-new Rembrandt, and it’s shockingly good” reads the title of a PC World article in April 2016. Advertising firm J. Walter Thompson unveiled a 3D printed painting called “The Next Rembrandt”, based on 346 paintings of the old master. Not just PC World, many more articles touted similar titles, presenting the painting to the public as if it were made by a computer, a 3D printer, Artificial Intelligence and deep learning. It is clear though that the programmers who worked on the project are not computers, and neither are the people who tagged the 346 Rembrandt paintings by hand. The painting was made by a team of programmers and researchers, and it took them 18 months to do so.
A very successful feat of advertising, and a great example of how eager we are to attribute human qualities to computers and see data as the magic powder bringing life to humanity’s most confusing tool. Data is the new black… it can touch our soul according to a Microsoft spokesperson on the website of the Next Rembrandt: “Data is used by many people today to help them be more efficient and knowledgeable about their daily work, and about the decisions they need to make. But in this project it’s also used to make life itself more beautiful. It really touches the human soul.” (Ron Augustus, Microsoft). We have elevated data to divine standards and have developed a tendency to confuse tools with their creators in the process. Nobody in the 17th Century would have dreamed of claiming a brush and some paint created The Night Watch, or that it’s a good idea to spend 18 months on one painting.
The anthropomorphisation of computers was researched in depth by Reeves and Nass in The Media Equation (1996). They show through multiple experiments how people treat computers, television, and new media like real people and places. On the back of the book, Bill Gates says Nass and Reeves show us some “amazing things”. And he was right. Even though test subjects were completely unaware of it, they responded to computers as they would to people, by being polite, cooperative, attributing personality characteristics such as aggressiveness, humour, expertise, and even gender. If only Microsoft would use this knowledge to improve the way people interact with their products, instead of using it for advertising campaigns promoting a belief in the magic powers of computers and data. Or… oh wait… This belief, combined with the anthropomorphising of computers, profoundly alters the way people interact with machines and makes it much more likely that users will accept and adapt to the limitations and demands of technology, instead of demanding technology should adapt to them.
Strangely enough, the anthropomorphising of computers goes hand in hand with attributing authority, objectivity, even superiority to computer output by obfuscating the human hand in its generation. It seems paradoxical to attribute human qualities to something, while at the same time considering it to be more objective than humans. How can these two beliefs exist side by side? We are easily fooled, ask any magician. As long as our attention is distracted, steered, you can hide things in plain sight. We haven’t been too bothered with this paradox in the past. The obfuscation of a human hand in the generation of messages that require an objective or authoritative feel is very old. As a species, we’ve always turned to godly or mythical agents, in order to make sense of what we did not understand, to seek counsel. We asked higher powers to guide us. These higher powers rarely spoke to us directly. Usually messages were mediated by humans: priestesses, shamans or oracles. These mediations were validated as objective and true transmissions through a formalisation of the process in ritual, and later institutionalised as religion, obfuscating the human hand in the generation of these messages. Although disputed, it is commonly believed that the Delphic oracle delivered messages from her god Apollo in a state of trance, induced by intoxicating vapours arising from the chasm over which she was seated. Possessed by her god the oracle spoke, ecstatically and spontaneously. Priests of the temple translated her words into the prophecies the seekers of advice were sent home with. Apollo had spoken.

Nowadays we turn to data for advice. The oracle of big data[1] functions in a similar way to the oracle of Delphi. Algorithms programmed by humans are fed data and consequently spit out numbers that are then translated and interpreted by researchers into the prophecies the seekers of advice are sent home with. The bigger the data set, the more accurate the results. Data has spoken. We are brought closer to the truth, to reality as it is, unmediated by us subjective, biased and error-prone humans. We seek guidance, just like our ancestors, hoping we can steer events in our favour. Because of this point of departure, very strong emotions are attached to big data analysis, feelings of great hope and intense fear. Visions of utopia, the hope that it will create new insights into climate change and accurate predictions of terrorist attacks, protecting us from great disaster. At the same time there are visions of dystopia, of a society where privacy invasion is business as usual, and through this invasion an ever increasing grip on people through state and corporate control, both directly and through unseen manipulation.
Let’s take a closer look at big data utopia, where the analysis of data will protect us from harm. This ideology is fed by fear and has driven states and corporations alike to gather data like there is no tomorrow or right to privacy, at once linking it very tightly to big data dystopia. What is striking is that the fear of terrorist attacks has led to lots of data gathering, the introduction of new laws and military action on the part of governments, yet the fear of climate change has led to only very moderate activity. Yet the impact of the latter is likely to have more far reaching consequences on humanity’s ability to survive. In any case, the idea of being able to predict disaster is a tricky one. In the case of global warming, we can see it coming and aggravating because it is already taking place. But other disasters are hard to predict and can only be explained in retrospect. In Antifragility, Nicolas Taleb (2013, pp.92-93), inspired by a metaphor of Bertrand Russell, quite brilliantly explains the tendency to mistake absence of evidence for evidence of absence with a story about turkeys. Turkeys are fed for a thousand days by a butcher, leading them to believe, backed up by statistical evidence, that butchers love turkeys. Right when the turkey is most convinced that butchers love turkeys, when it is well fed and everything is quiet and predictable, the butcher surprises the turkey which has to drastically revise its beliefs.
An only slightly more subtle version of big data utopia is a utopia where data can speak, brings us closer to reality as it is, where we can safely forget theory and ideas and other messy subjective human influences through crunching enormous amounts of numbers.
“This is a world where massive amounts of data and applied mathematics replace every other tool that might be brought to bear. Out with every theory of human behaviour, from linguistics to sociology. Forget taxonomy, ontology, and psychology. Who knows why people do what they do? The point is they do it, and we can track and measure it with unprecedented fidelity. With enough data, the numbers speak for themselves.” (Anderson, 2008)
Using this rhetoric, there is no more need for models or hypotheses, correlation is enough. Just throw in the numbers and the algorithms will spit out patterns that traditional scientific methods were unable to bring to light. This promise sells well and companies providing data analysis and storage services promote it with great enthusiasm, as demonstrated by two slides in an Oracle presentation at Strata 2015: “Data Capital is the land grab of the future” and “It’s yours for the taking” (Pollock, 2015).
Can numbers really speak for themselves? When taking a closer look, a lot of assumptions come to light, constructing the myth of the oracle. Harford (2014) describes these assumptions as four articles of faith. The first is the belief in uncanny accuracy. This belief focuses all attention on the cases where data analysis made a correct prediction, while ignoring all false positive findings. Being right one out of ten times may still be highly profitable for some business applications, but uncannily accurate it is not. The second article is the belief that not causation, but correlation matters. The biggest issue with this belief is that if you don’t understand why things correlate, you have no idea why they might stop correlating either, making predictions very fragile in an ever changing world. Third is the faith in massive data sets being immune to sampling bias, because there is no selection taking place. Yet found data contains a lot of bias, as for example not everyone has a smartphone, and not everyone is on Twitter. Last but not least, the fourth belief, that numbers can speak for themselves… is hard to cling to when spurious correlations create so much noise, it’s hard to filter out the real discoveries. Taleb (2013, p.418) points to the enormous amount of cherry-picking done in big data research. There are way too many variables in modern life, making spurious relations grow at a much faster pace than real information.
As a rather poetic example, Leinweber (2007) demonstrated that data mining techniques could show a strong but spurious correlation between the changes in the S&P 500 stock index and butter production in Bangladesh. There is more to meaningful data analysis than finding statistical patterns, which show correlation rather than causation. Boyd and Crawford describe the beliefs attached to big data as a mythology, “the widespread belief that large data sets offer a higher form of intelligence and knowledge that can generate insights that were previously impossible, with the aura of truth, objectivity, and accuracy” (Boyd and Crawford, 2012). The belief in this oracle has quite far reaching implications. For one, it dehumanises humans by asserting that human involvement through hypotheses and interpretation, is unreliable, and only by removing humans from the equation can we finally see the world as it is. While putting humans and human thought on the sideline, it obfuscates the human hand in the generation of its messages and anthropomorphises the computer by claiming it is able to analyse, draw conclusions, even speak to us. The practical consequence of this dynamic is that it is no longer possible to argue with the outcome of big data analysis. This becomes painful when you find yourself in the wrong category of a social sorting algorithm guiding real world decisions on insurance, mortgage, work, border checks, scholarships and so on. Exclusion from certain privileges is only the most optimistic scenario, more dark ones involve basic human rights.
The deconstruction of this myth was attempted as early as 1984. In “A Spreadsheet Way of Knowledge”, Stephen Levy describes how the authoritative look of a spreadsheet, and the fact that it was done by a computer, has a strong persuasive effect on people, leading to acceptance of the proposed model of reality as gospel. Levy points out that all the benefits of using spreadsheets are meaningless if the metaphor is taken too seriously. He concludes with a statement completely opposite to what Anderson will state 24 years later: “Fortunately, few would argue that all relations between people can be quantified and manipulated by formulas. Of human behaviour, no faultless assumptions – and so no perfect model — can be made”. A lot has changed in 24 years. Still back in the eighties, Theodore Roszak describes the subjective core of software beautifully: “Computers, as the experts continually remind us, are nothing more than their programs make them. But as the sentiments above should make clear, the programs may have a program hidden within them, an agenda of values that counts for more than all the interactive virtues and graphic tricks of the technology. The essence of the machine is its software, but the essence of the software is its philosophy” (Roszak, 1986). This essence, sadly, is often forgotten, and outcomes of data analysis therefore misinterpreted. In order to correctly assess the outcomes of data analysis it is essential to acknowledge that interpretation is at the heart of the process, and assumptions, bias and limitations are undeniable parts of it.
In order to better understand the widespread belief in the myth of big data, it is important to look at the shift in the meaning of the word information (Roszak, 1986). In the 1950s, with the advent of cybernetics, the study of feedback in self-regulating closed systems, information transformed from short statement of fact to the means to control a system, any system, be it mechanical, physical, biological, cognitive or social (Wiener, 1950). In the 1960s artificial intelligence researchers started viewing both computers and humans as information processing systems (Weizenbaum, p.169). In the 1970s it was granted an even more powerful status, that of commodity. The information economy was born and promoted with great enthusiasm in the 1980s.
“Reading Naisbitt and Toffler is like a fast jog down a world’s Fair Midway. We might almost believe, from their simplistic formulation of the information economy, that we will soon be living on a diet of floppy disks and walking streets paved with microchips. Seemingly, there are no longer any fields to till, any ores to mine, any heavy industrial goods to manufacture; at most these continuing necessities of life are mentioned in passing and then lost in the sizzle of pure electronic energy somehow meeting all human needs painlessly and instantaneously.” (Roszak, 1986, p. 22).
Nowadays not only corporations and governments, but individuals have become information hungry. What started as a slightly awkward hobby in the 80s, the quantified self has now become mainstream with people self monitoring anything from sleep to eating habits, from sport activities to mood using smartphones and smartwatches with build-in sensors, uploading intimate details such as heart-rate, sleep patterns and whereabouts to corporate servers in order to improve their performance.
Even with this change in the way we view information in mind, it is difficult to believe we cannot see through the myth. How did it become plausible to transpose cybernetic thinking from feedback in self-regulating closed systems to society and even to human beings? It is quite a leap, but we somehow took it. Do humans have anything in common with such systems? Weizenbaum (1976) explains our view of man as machine through our strong emotional ties to computers, through the internalisation of aspects of computers in order to operate them, in the form of kinaesthetic and perceptual habits. He describes how in that sense, man’s instruments become part of him and alter the nature of his relationship to himself. In The Empty Brain (2016) research psychologist Robert Epstein writes about the idea that we nowadays tend to view ourselves as information processors, but points out there is a very essential difference between us and computers: humans have no physical representations of the world in their brains. Our memory and that of a computer have nothing in common, we do not store, retrieve and process information and we are not guided by algorithms.
Epstein refers to George Zarkadakis’ book In Our Own Image (2015), where he describes six different metaphors people have employed over the past 2,000 years to try to explain human intelligence. In the earliest one, eventually preserved in the Bible, humans were formed from clay or dirt, which an intelligent god then infused with its spirit. This spirit somehow provided our intelligence. The invention of hydraulic engineering in the 3rd century BC led to the popularity of a hydraulic model of human intelligence, the idea that the flow of different fluids in the body – the ‘humours’ – accounted for both our physical and mental functioning. By the 1500s, automata powered by springs and gears had been devised, eventually inspiring leading thinkers such as René Descartes to assert that humans are complex machines. By the 1700s, discoveries about electricity and chemistry led to new theories of human intelligence – again, largely metaphorical in nature. In the mid-1800s, inspired by recent advances in communications, the German physicist Hermann von Helmholtz compared the brain to a telegraph. Predictably, just a few years after the dawn of computer technology in the 1940s, the brain was said to operate like a computer, with the role of physical hardware played by the brain itself and our thoughts serving as software.
This explanation of human intelligence, the information processing metaphor, has infused our thinking over the past 75 years. Even though our brains are wet and warm, obviously an inseparable part of our bodies, and using not only electrical impulses but also neurotransmitters, blood, hormones and more, nowadays it is not uncommon to think of neurons as ‘processing units’, synapses as ‘circuitry’, ‘processing’ sensory ‘input’, creating behavioural ‘outputs’. The use of metaphors to describe science to laymen also led to the idea that we are ‘programmed’ through the ‘code’ contained in our DNA. Besides leading to the question of who the programmer is, these metaphors make it hard to investigate the nature of our intelligence and the nature of our machines with an open mind. They make it hard to distinguish the human hand in computers, from the characteristics of the machine itself, anthropomorphising the machine, while at the same time dehumanising ourselves. For instance, Alan Turing’s test to prove if a computer could be regarded as thinking, now is popularly seen as a test that proves if a computer is thinking. Only in horror movies would a puppeteer start to perceive his puppet as an autonomous and conscious entity. The Turing test only shows whether or not a computer can be perceived of as thinking by a human. That is why Turing called it the imitation game. “The Turing Test is not a definition of thinking, but an admission of ignorance — an admission that it is impossible to ever empirically verify the consciousness of any being but yourself.” (Schulman, 2009). What a critical examination of the IP metaphor makes clear, is that in an attempt to make sense of something we don’t understand, we’ve invented a way of speaking about ourselves and our technology that obscures instead of clarifies both our nature and that of our machines.
Why dehumanize and marginalize ourselves through the paradox of viewing ourselves as flawed, wanting a higher form of intelligence to guide us, envisioning superhuman powers in a machine created by us, filled with programs written by us, giving us nothing but numbers that need interpretation by us, obfuscating our own role in the process yet viewing the outcome as authoritative and superior. A magician cannot trick himself. Once revealed, never concealed. Yet we manage to fall for a self created illusion time and time again. We fall for it because we want to believe. We joined the church of big data out of fear, in the hope it would protect us from harm by making the world predictable and controllable. With the sword of Damocles hanging over our heads, global warming setting in motion a chain of catastrophes, threatening our survival, facing the inevitable death of capitalism’s myth of eternal growth as earth’s resources run out, we need a way out. Since changing light bulbs didn’t do the trick, and changing the way society is run seems too complicated, the promise of a technological solution inspires great hope. Really smart scientists, with the help of massive data sets and ridiculously clever AI will suddenly find the answer. In ten years time we’ll laugh at the way we panicked about global warming, safely aboard our CO2 vacuum cleaners orbiting a temporarily abandoned planet Earth.
Theinformation processing metaphor got us completely hooked on gathering data. We are after all information processors. The more data at our fingertips, the more powerful we become. Once we have enough data, we will finally be in control, able to predict formerly unforeseen events, able to steer the outcome of any process because for the first time in history we’ll understand the world as it really is. False hope. Taken to itsextreme, the metaphor leads to the belief that human consciousness, being so similar to computer software, can be transferred to a computer.
“One prediction – made by the futurist Kurzweil, the physicist Stephen Hawking and the neuroscientist Randal Koene, among others – is that, because human consciousness is supposedly like computer software, it will soon be possible to download human minds to a computer, in the circuits of which we will become immensely powerful intellectually and, quite possibly, immortal.” (Epstein, 2016).
False hope. Another example is the project Alliance to Rescue Civilization (ARC), by scientists E. Burrows and Robert Shapiro. It is a project that aims to back up human civilization in a lunar facility. The project artificially separates the “hardware” of the planet with its oceans and soils, and the “data” of human civilization (Bennan, 2016). Even thoughseeing the need to store things off-planet conveys aless than optimisticoutlook on the future, the project gives the false impression that technology can separate us from earth. A project pushing this separation to its extreme is Elon Musk’s SpaceX plan to colonize Mars, announced in June 2016, and gaining momentum with his presentation at the 67th International Astronautical Congress in Guadalajara, September 27th. The goal of the presentation was to make living on Mars seem possible within our lifetime. Possible, and fun.
“It would be quite fun because you have gravity, which is about 37% that of Earth, so you’d be able to lift heavy things and bound around and have a lot of fun.” (Musk, 2016).
We are inseparable from the world we live in. An artificial separation from earth, which we are part of and on which our existence depends, will only lead to a more casual attitude towards the destruction of its ecosystems. We‘ll never be immortal, downloadable or rescued from a lunar facility in the form of a back up. Living on Mars is not only completely impossible at this moment, nothing guarantees it will bein the future. Even if it were possible, and you would be one of the select few that could afford to go, you’d spend your remaining days isolated on a life-less, desolate planet, chronically sleep deprived, with a high risk of cancer, a bloated head, the bone density and muscle mass worse than that of a 120 year old, due to the small amount of gravity and high amount of radiation (Chang, 2014).Just like faster and more precise calculations regarding the position of planets in our solar system will not make astrology more accurate in predicting the future, faster machines, more compact forms of data storage and larger data setswill not make us able to predict and control the future. Technological advances will not transform our species from a slowly evolving one, into one that can adapt to extreme changes in our environmentinstantly, as we would need to in the case of a rapidly changing climate or a move to another planet.
These are the more extreme examples, that are interesting because they make the escapist attitude to our situation so painfully clear. Yet the more widely accepted beliefs are just as damaging. The belief that with so much data at our fingertips, we’ll make amazing new discoveries that will safe us just in time, leads to hope that distracts us from the real issues that threaten us. There are 7.4 billion of us. The earth’s resources are running out. Climate change will set in motion a chain of events we cannot predict precisely but dramatic sea level rises and mass extinction will be part of it without doubt. We cannot all Houdini out of this one, no matter how tech savvy we might become in the next decades. Hope is essential, but a false sense of safety paralyses us and we need to start acting. In an attempt to understand the world, to become less fragile, in the most rational and scientifically sound way we could think of, we’ve started anthropomorphising machines and dehumanising ourselves. This has, besides inspiring a great number of Hollywood productions, created a massive blind spot and left us paralysed. While we are bravely filling up the world’s hard disks, we ignore our biggest weakness: this planet we are on, it’s irreplaceable and our existence on it only possible under certain conditions. Our habits, our quest to become more productive, more efficient, more safe, less mortal, more superhuman, actually endangers us as a species… With technology there to save us, there is no urgency to act. Time to dispel the myth, to exit the church of big data and start acting in our best interest, as a species, not as isolated packages of selfish genes organized as information processors ready to be swooshed off the planet in a singularity style rapture.

Featured Image: Black Shoals: Dark Matter’, Joshua Portway, Lise Autogena, Big Bang Data.
Big Bang Data is a major travelling exhibition currently set within London’s Somerset House. That a large institution is presenting a journey via data capture through ‘selfies, surveillance and infographics’ is in itself an interesting patchwork of intent and realisation. The aim of the exhibition is to ‘demystify data’. This is a grand, summative and in actuality slightly awkward claim which, in my view, encapsulates the character of an interesting, textured exhibition in an unintentionally astute way.
As Big Bang Data is dedicated to revealing data comprehensively through its various architectures and iterations, it makes sense for the underrepresented materiality of information to have prominence early on. This materiality, perhaps inevitably, was compromised in the gallery space. Entering the first room brings you face to face with Timo Arnall’s Internet Machine, which takes the form of multiscreen video documentation of not just the machines, but also the architecture, which supports mobile telephony.

I would have loved to have experienced the spaces shown more intimately and walked around one of these structures; the installation was illuminating but I was still most certainly watching at a remove. This initial interplay of removal and involvement is central to the way we experience data. How can people begin to understand something which exists as multiple codes and flows, on a scale and at a speed which is not concerned with making itself understood by humans? What form could an understanding of data possibly take? When learning about something this far from our grasp, it seems that ‘understanding’ must be replaced by ‘awareness’. Rather than seeking one answer via one route the visitor to Big Bang Data has to build an impression, obviously subjective and subject to change.
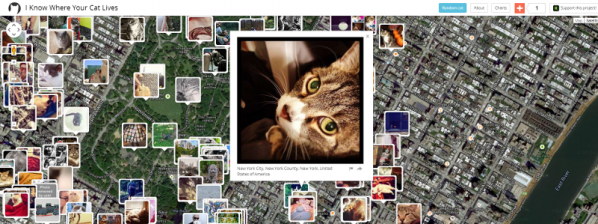
In its quest to expose and explain data’s social and cultural uses, it presents a fairly overwhelming amount of information. It is interesting to walk through the space thinking about how this information has been channeled by each specific project. Some representations, such as Owen Mundy’s ‘I Know Where Your Cat Lives’, link distant people and spaces via connected points, while others such as Phillip Adrian’s ‘One Second’ capture in great detail one specific point in time and space.

Julian Oliver’s ‘Transparency Grenade’ brings together graphical, console and physical representations of data to offer a transportable means of leaking information as a response to impenetrable governing systems. Each of the works on display demonstrates a negotiation between temporality, materiality and spatiality, and often one is sidelined in favour of the other. Again, considering the exhibition in this way is also to consider the world of data in all its contrariness.

Data manifests itself at the same time locally and globally. As well as addressing specificity, the projects shown in Big Bang Data dwell repeatedly on scale. Works such as Tejka’s ‘London Data Streams’ and Nicholas Felton’s ‘Annual Reports’ pit scales against each other to cast light on the filters through which data is processed.

Ingo Günther’s ‘World Processor’ and Forensic Architecture’s ‘Liquid Traces: The Left-To-Die Boat Case’ are examples of resonant, atypical data visualisations which mutate familiar imagery and present alternative summaries of events. The section entitled ‘Data For The Common Good’ shows some of the ways data is being actively used in society to empower citizens with works such as Safecast’s ‘bGeigie Nano’ and IF’s ‘Data Licenses’, while a series of video interviews with journalists and other professionals working with data illuminate the processes through which information becomes communication.

The previously mentioned tension between object and their presentation recurs at various points throughout the exhibition, a great example being the array of undersea telephone cables, presented in cases of wood and glass which could have been magpied from a display of historical artifacts (each cable segment has a number next to it which corresponds to a factual description). It felt strange not being able to touch them. A work which I felt fully occupied, and knowingly played with, its surroundings was Ellie Harrison’s vending machine, which sits unassumingly in the gift shop; its secret is that when search terms connected to the recession make the headlines, free snacks are dispensed. Its presence in a exhibition on data in a gallery space felt appropriate.

Big Bang Data, which runs alongside a programme of events and has previously been exhibited at CCCB in Barcelona, comes at a moment where large organisations are more frequently bringing concepts such as surveillance, open source and free software into public spaces. There is a great need to bring the concepts and processes surrounding data more wholly into the public eye, and this exhibition strikes me as, overall, a big step in a good direction. It makes real and challenging efforts to bring together world-spanning processes, complex concepts and extremely diverse content into an exhibition space. The task of the exhibition’s curatorial and production teams must have been difficult.
Of course the challenges they faced have been dealt with before many times in many ways, and of course the practical decision-making involved in producing an exhibition invariably creates tension points. The reason I’ve dwelt on the problems of the organisers here is that the tensions evidenced within the space at Somerset House say much not just about the response of the publicly funded arts to data but also about the nature of data itself. The exhibition turns into at times a museum, a bedroom, a classroom, an information point, a scruffy new gallery space and a state of the art new media space. In bringing together the story of data the exhibition also brings together the story of representation in space more generally.
In writing about Big Bang Data I have had to choose to highlight certain works and not others. Your interpretation will be entirely different from mine, which is as it should be where data and cultural inclusion is concerned. What’s important is that the exhibition’s prominence and texture opens up conversation and critique. The exhibition is detailed, procedural and expansive. It is also alive with contrariness, generality and awkwardness. Perhaps one of the great things about the show is that these qualities are left to jostle for space. For me, reading this exhibition as a performative event was useful; others may leave Somerset House with an entirely different view having taken an entirely different route. This is inevitable where data is concerned – learning is incremental and procedural, but not traditionally linear.
French artists Émilie Brout and Maxime Marion contribute three pieces to The Human Face of Cryptoeconomies exhibition. Gold and Glitter is a painstakingly assembled installation of collaged GIFs. Previous installations have featured the GIFs displayed on a gold iPad atop a pile of collected gold trinkets; at Furtherfield Gallery now a single golden helium balloon hovers in front of a floor to ceiling projection. Nakamoto (The Proof) is video documentation of the artists’ efforts to try and place a face on the elusive Bitcoin creator, Satoshi Nakamoto (but is it his face in the end? We don’t know). Untitled SAS is a registered French company without employees and whose sole purpose is to exist as a work of art.
Brout and Marion’s work can be situated among artists and art practices who have grappled with how to think about value and objects—or more precisely, how objects are inscribed (and sometimes not) into an idea of what is valuable. In a recent article for Mute Magazine, authors Daniel Spaulding and Nicole Demby point out that “Value is a specific social relation that causes the products of labor to appear and to exchange as equivalents; it is not an all-penetrating miasma.”1 Value is a process by which bodies are sorted and edited but it is not a default spectrum on to which all bodies must fall in varying degrees. This clarification makes explicit the fact that while the relationships productive of value allow “products of labor to appear and to [be exchanged]”2 this is not an effect that is extended to all products of labor. Attempts to isolate the underlying logic of this sorting mechanism are often at the heart of art practices dealing with questions of value and commodification. Like Andy Warhol’s Brillo Boxes or Marcel Duchamp’s Fountain, these artworks become interesting problematics for the question of art and value for the ways in which they are able to straddle two economic realms—that of the art object and the commercial object—while resisting total inclusion in either.
The Human Face of Cryptoeconomies picks up these themes in an art context and repositions them alongside digital cultures and emerging digital economies. In Brout and Marion’s work alone, concepts of kitsch, identity, and human capital have been inhabited and imported from their originary realms into the digital. Answering questions remotely, Brout and Marion were kind enough to give us some insights into their work and process. My goal here has been to draw out some points about the operation of value that are at work in Brout and Marion’s practice, as well as to point towards an idea of how value is transformed, or even mutated, in the digital age.
* * *

Brout and Marion open up with an interesting provocation. They explain, “When we showed the project [Glitter and Gold] in Paris this year, people stole a lot of objects, even if they were very cheap. Gold has an incredible power of attraction.”
It is telling, to some extent, that Brout and Marion’s meditations on gold have an almost direct link to the visual metaphor used by Clement Greenberg in his 1939 essay Avante-Garde and Kitsch to describe the relation between culture—epitomized in the avant-garde—and the ruling class. Greenberg writes, “No culture can develop without a social basis, without a source of stable income. And in the case of the avant-garde, this was provided by an elite among the ruling class of that society from which it assumed itself to be cut off, but to which it has always remained attached by an umbilical cord of gold.”3 This relation is subverted in Gold and Glitter, which takes for its currency—its umbilical cord of gold—a kind of unquantifiable labor that is seemingly (and perhaps somewhat sinisterly) always embedded in discussions of the digital.
For Greenberg, kitsch always existed in relation to the avant-garde; one fed and supported the other, even if the way in which that relation of sustenance worked was by negation. And while Greenberg’s theory relies on his own strict allegiances to hierarchical society, privileged classes, the values of private property, and all the other divisive tenets of capitalism that we now know all too well can be destructive. Kitsch remains useful to us for the ways in which it allows the means of production to enter into a consideration of aesthetics. Here the recent writing of Boris Groys can be useful. In an essay written for e-flux titled Art and Money, Groys makes a compelling case for why we should persist in a sympathetic reading of Greenberg. He argues that Greenberg’s incisions amongst the haves and have nots of culture can be cut across different lines; that because Greenberg identifies avant-garde art as art that is invested in demonstrating the way in which is it is made and it doesn’t allow for its evaluation by taste. Avant-garde art shows its guts to us all, and on equal terms—“its productive side, its poetics, the devices and practices that bring it into being” and inasmuch “should be analyzed according the same criteria as objects like cars, trains, or planes.”4
For Groys this distinction situates the avant-garde within a constructivist and productivist context, opening up artworks themselves to be appreciated for their production, or rather, “in terms that refer more to the activities of scientists and workers than to the lifestyle of the leisure class.”5 In this way Glitter and Gold, like Brout and Marion’s other artworks, is to be appreciated not for any transcendent reason but rather for the means by which it came into existence. ‘The processes of searching and collaging golden GIFs sit side by side with the physical work of accumulating the golden trinkets for display: “We collected these objects for a long time” the artists explain, “some were personal objects (child dolphin pendant, in true gold), others were given or found in flea markets, bought in bazaars … We wanted to have a lot of different types and symbols, from a Hand of Fatima to golden chain, skulls, butterflies, etc.”

Furthermore, Glitter and Gold can be understood as the product of compounding labors: the labor of Brout and Marion in collecting their artifacts, the labor necessary to create the artifacts, the labor of GIF artists, the labor of searching for said GIFs, the labor of weaving a digital collage. These on-going processes forge, trace, and re-trace paths during which, at some point, gold takes on the function as aesthetic shorthand for value. As Brout and Marion explain, “Here the question is more about the intrinsic values we all find in Gold, even when it just looks like gold. Gold turns any prosaic product into something desirable. [Gold and Glitter] is less about economics than about perceived value.”
Groys provides his reading of Greenberg as a means of pointing towards a materiality that is always in excess of existing coordinates of value. If value always reveals the products of labor as they enter into a zone of exchange, it is something else proper to contemporary art that reveals another materiality beyond this exchange. For Groys, this something else is at work in the dynamics of art exhibition, which can render visible otherwise invisible forces and their material substrates. This is certainly a potential that is explored by Brout and Marion. In Nakamoto (The Proof), the viewer can watch the artists’ attempt at creating a passport for the infamous and elusive Bitcoin creator Satoshi Nakamoto. At present, it is unclear whether Nakamoto is a single person or group of people, though the Nakamoto legacy as creator of Bitcoin, a virtual currency widely used on darknets, is larger than life. Adding to this myth, after publishing the paper to kickstart bitcoin via the Cryptography Mailing List in 2008, and launching the Bitcoin software client in 2009, Nakamoto has only sporadically been seen participating in the project with others via mailing lists before making a final, formal disappearance in 2011, explaining that he/she/they had “moved on to other things.”6 Nakamoto’s disappearance, coupled with the fact that Nakamoto’s estimated net worth must be somewhere in the hundred millions Euros, has given rise to the modern-day myth of Nakamoto, and with it an insatiable curiosity to uncover the identity and whereabouts of the elusive Bitcoin creator.

Brout and Marion make their own attempt to summons the mysterious Nakamoto back to life by putting together the evidence of Nakamoto’s existence and procuring a Japanese passport using none other than the technologies that Nakamoto’s Bitcoin both imparted and facilitated. When asked if they feared for their own self-preservation in seeing this project through, Brout and Marion answered, “Yes, even if we were pretty sure that it would be easy to prove our intention to the authorities, and that the fake passport couldn’t be useful to anybody, buying a fake passport is still illegal.” They add, “But we also wanted to play the game entirely, so we made every possible effort to preserve our anonymity during our journey on the darknets.”
However Brout and Marion have yet to receive the passport; as they explain, “The last time we received information, the document was in transit at the Romanian border.” When asked if they expect to receive the passport, they respond, “No, today we think we will never receive it. We are completely sure that it has existed, but we’ll surely never know what happened to it.” What, then, will they do if they never receive the passport? “Maybe just continue to exhibit the only proof of it we have!” they exclaim. “There is something beautiful in it: we tried to create a physical proof of the existence of a contemporary myth, using digital technology and digital money, and the only thing we have is a scan!”
If Brout and Marion’s nonchalance seems unexpected then it is because the disappearance of the passport for the artists marks just another ebb in the overall flow of their piece; a flow that began with Nakamoto, coursed through their clandestine chats via a Tor networked browser and high security email, and now continues to trickle on while we wait in anticipation for the next chapter of the Nakamoto passport to reveal itself. In this respect, the anticipation of the passport is a poetic and unforeseen layer added to the significance of the piece: “Maybe it is even better [that the passport should not arrive]” Brout and Marion comment. “It’s like it was impossible to bring Nakamoto out of the digital world.”

If value is always formed by way of a social relation, then how do digital modes of sociality also deliver this effect? This becomes a particularly fraught question when considering that, as Anna Munster has written, the sociality that takes place on the internet can be understood as the interrelation of any number of subjectivities, both organic and inorganic. Brout and Marion’s ambivalence to the purloined passport highlights just such an expectation: “Here the lack of identity delivers a lot of value. Look at Snowden: journalists ask him more about his girlfriend than about his revelations. Making something as big as Bitcoin and staying perfectly anonymous? These are strong attacks to two of the most important issues of our societies: banks and privacy.” What their statement suggests is how a collective movement towards transgression, here seen as compounding maneuvers of avoidance of physical world boundaries and institutions, might hold within it the promise of its own set of value coordinates. As Brout and Marion further explain: “For us, Nakamoto is absolutely fascinating. The efforts he made to prevent himself from being turned into a product are incredible. Especially when you know the importance of [Bitcoin’s] creation, and that only a few men in the world are smart enough to create something like this. Adding to that the fact that Nakamoto is probably a millionaire, you have one of the only true contemporary myths, something hard to find credible even if it was just a fictional character in a movie. So this somewhat absurd attempt to create a proof of Nakamoto’s existence was, for us, an attempt to make a portrait of him, to put light on his figure. And, in some ways, a tribute.”
Brout and Marion mount a final probe into questions of value in their piece, Untitled SAS. Untitled SAS is the name for Brout and Marion’s corporation whose purpose and medium is to exist as a work of art. In France SAS means société par actions simplifée, and is the Anglophone equivalent of an LTD. SAS companies have shares that can be freely traded between shareholders. Untitled SAS, in Brout and Marion’s own words, “has no other purpose than to be a work of art: it won’t buy or sell anything, there won’t be employees, its existence is an end it itself. The share capital of the company is 1 Euro (the minimum), and we edited 10,000 shares owned by us (5,000 for each one). Everybody can freely buy and sell shares of this company.” Brout and Marion are clear: in no uncertain terms, “Untitled SAS is a work of art where the medium is a real company, and the corporate purpose of this company is simply to be a work of art.”

Untitled SAS is a tongue in cheek commentary on the situating of artworks as outside of the rational space of the market while still being subject to selective norms of economic behavior. Brout and Marion explain, “Untitled SASis obviously a metaphor for the art market, and the market in general: it is a true, fully legal, and functional speculation bubble. Companies usually try to create some concrete value, they are means. The art world has fewer rules than the regular market, the price of some artworks can radically change in few days without any logical reason: their intrinsic value is completely uncorrelated to their market value. We wanted to reproduce and play with these systems in the scale of an artwork.” At this level, what Brout and Marion uncover is further proof of the condition of the contemporary art period as Groys sees it: a time in which “mass artistic production [follows] an era of mass art consumption” and by extension “means that today’s artist lives and works primarily among art producers—not among art consumers.”7

Crucially, the effect of this condition is that contemporary professional artists “investigate and manifest mass art production, not elitist or mass art consumption.” This is the mode of art making precisely employed by Brout and Marion in the creation of Untitled SAS. It has the added effect, too, of creating an artwork that can exist outside the problem of taste and aesthetic attitude. Companies tend to eschew taste qualifications in favor of brand associations. Untitled SAS becomes readable as an artwork, as Untitled SAS, when the expectations and regulations of a nationally recognized business are made to butt up against the inconsistencies of the artworld as an economic sphere. The art object then becomes rather a means of accessing the overlapping paths of art and value as they are uniquely enabled to circulate in and out of the art & Capitalist markets.
* * *
Brout and Marion note that, “In our work we often use algorithms and generative ways to produce things, but here we wanted to something no machine can do, something hand-made, too, finally a simple and traditional work of art.” These kinds of generative technological processes and sorting algorithms have been central to many debates on how contemporary culture is absorbing the boon of big data: from ethical questions on predictive policing to dating apps and ride-hailing startups. As one Slate article posed the question in relation to Uber, these algorithms are more than just quick and efficient modes of labor—they are reflections of the marketplace themselves.
So what, then, might it mean that both values and services in the digital age are predicated on the power to sort and categorize, and that this power is ciphered through its own dynamic of social relations, but that in one scenario what emerges is a sphere of the valuable and in the other a software that asserts itself as benign and at the behest of an impartial, impersonal data? Perhaps the rationality of value and market circulation vis a vis the art object was always going to be a little too tricky to take on: too many exceptions, too many questions of subjectivity, taste, and judgment. But as the works exhibited for The Human Face of Cryptoeconomies might suggest the rationality of value and the products it chooses to incorporate is of high importance. If value works precisely because of the specific interrelating of social subjects then we can consider the realm of the digital as a concentrated form of such a relation.
Against this we must consider the new subject that is produced and addressed by the intersecting of these discussions. Spaulding and Demby make the case that, that “Art under capitalism is a good model of the freedom that posits the subject as an abstract bundle of legal rights assuring formal equality while ignoring a material reality determined by other forms of systematic inequality.”8 Karen Gregory, in The Datalogical Turn, writes, “In the case of personal data, it is not the details of that data or a single digital trail that are important, it is rather the relationship of the emergent attitudes of digital trails en mass that allow for both the broadly sweeping and the particularised modes of affective measure and control. Big data doesn’t care about ‘you’ so much as the bits of seemingly random information that bodies generate or that they leave as a data trail”.
The works of Brout and Marion exhibited at the Human Face of Crypotoeconomies exhibition places the intimacy of the body front and center. They speak to the shadow and trace of the body by appropriating the paths of the faceless, or by giving a face to the man (or entity) without a body, to becoming the human face of the market player par excellence by inserting themselves into a solipsistic art corporation. Brout and Marion’s practice understands that while value may not be an all-penetrating miasma, this is not also to say that the effect of value is not still inscribed on the flesh of each and all, organic or not.
1 Demby, “Art, Value, and the Freedom Fetish | Mute.”
2 Ibid.
3 Greenberg, “Avant-Garde and Kitsch,” 543.
4 Ibid.
5 Ibid.
6 “Who Is Satoshi Nakamoto?”
7 Groys, “Art and Money.”
8 Ibid.
DOWNLOAD
PRESS RELEASE (pdf)
‘Agliomania, eating and trading my stinky roses’ by Shu Lea Cheang. Courtesy of the artist and MDC #76 We Grow Money, We Eat Money, We Shit Money.
SEE IMAGES FROM THE PRIVATE VIEW
Featuring Émilie Brout and Maxime Marion, Shu Lea Cheang, Sarah T Gold, Jennifer Lyn Morone, Rhea Myers, The Museum of Contemporary Commodities (MoCC), the London School of Financial Arts and the Robin Hood Cooperative.
Furtherfield launches its Art Data Money programme with The Human Face of Cryptoeconomies, an exhibition featuring artworks that reveal how we might produce, exchange and value things differently in the age of the blockchain.
Appealing to our curiosity, emotion and irrationality, international artists seize emerging technologies, mass behaviours and p2p concepts to create artworks that reveal ideas for a radically transformed artistic, economic and social future.

Have you ever looked for faces in the clouds, or in the patterns in the wallpaper? Well, Facecoin is an artwork that is a machine for creating patterns and then finding ‘faces’ in them. It is both an artwork AND a prototype for an altcoin (a Bitcoin alternative).
Facecoin creates patterns by taking the random sets of data used to validate Bitcoin transactions and converting them into grids of 64 grayscale pixels. It then scans each pixel grid, picking out the ones that it recognises by matching its machine-definition of a human face. Facecoin uses the production of “portraits” (albeit by a machine) as a proof-of-aesthetic work. Facecoin is a meditation on how we discern and value art in the age of cryptocurrencies.
Shareable Readymades are iconic 3D printable artworks for an era of digital copying and sharing.
Duchamp put a urinal in a gallery and called it art, thereby transforming an everyday object and its associated value. Rhea Myers takes three iconic 20th century ‘readymades’ and transforms their value once again. By creating a downloadable, freely licensed 3D model to print and remix, everyone can now have their own Pipe, Balloon Dog and Urinal available on demand. Click here to collect your own special edition version of these iconic artworks.
A hoard of golden trinkets to appeal to our inner Midas. An image projection of found GIFs, collected from the internet, creates a gloriously elaborate, decorative browser-based display hosted at www.goldandglitter.net. It prompts reflections on the value of gold in an age where the value of global currencies are underpinned primarily by debt, and where digital currencies are mined through the labour of algorithms.
Also by Émilie Brout and Maxime Marion:
Nakamoto (The Proof) – a video documenting the artists’ attempt to produce a fake passport of the mysterious creator of Bitcoin, Satoshi Nakamoto.
Untitled SAS – a registered company with 10,000 shares that is also a work of art. SAS is the French equivalent of Corp or LTD. http://www.untitledsas.com/en
Jennifer Lyn Morone™ Inc reclaims ownership of personal data by turning her entire being into a corporation.

The Museum of Contemporary Commodities by Paula Crutchlow and Dr Ian Cook treats everyday purchases as if they were our future heritage. The project is being developed with local groups in Finsbury Park in partnership with Furtherfield.

The Alternet by Sarah T Gold conceives of a way for us to determine with whom, and on what terms, we share our data.

Shu Lea Cheang anticipates a future world where garlic is the new social currency.

Also, as part of Art Data Money, join us for data and finance labs at Furtherfield Commons.
LAB #1
Share your Values with the Museum of Contemporary Commodities
Saturday 17 October, 10:30am-4:30pm
A popular, data walkshop and lego animation event around data, trade, place and values in daily life.
Free – Limited places, booking essential
LAB #2
Breaking the Taboo on Money and Financial Markets with Dan Hassan (Robin Hood Coop)
Saturday 14 & Sunday 15 November, 11:00-5:00pmA weekend of talks, exercises and hands-on activities focusing on the political/social relevance of Bitcoin, blockchains, and finance. All participants will be given some Bitcoin.
£10 per day or £15 for the weekend – Limited places, booking essential
LAB #3
Building the Activist Bloomberg to Demystify High Finance with Brett Scott and The London School of Financial Arts
Saturday 21 & Sunday 22 November, 11:00-5:00pm
A weekend of talks, exercises and hands on activities to familiarise yourself with finance and to build an ‘activist Bloomberg terminal’.
£10 per day or £15 for the weekend – Limited places, booking essential
LAB #4
Ground Truth with Dani Admiss and Cecilia Wee
Saturday 28 November, 11-5pm
Exploring contemporary ideas of digital agency and authorship in post-digital society.
LAB #5
DAOWO – DAO it With Others
November/February
DAOWO – DAO it With Otherscombines the innovations of Distributed Autonomous Organisations (DAO) with Furtherfield’s DIWO campaign for emancipatory networked art practices to build a commons for arts in the network age.
Émilie Brout & Maxime Marion (FR) are primarily concerned with issues related to new media, the new forms that they allow and the consequences they entail on our perception and behaviour.Their work has in particular received support from the François Schneider Foundation, FRAC – Collection Aquitaine, CNC/DICRéAM and SCAM. They have been exhibited in France and Europe, in places such as the Centquatre in Paris, the Vasarely Foundation in Aix-en-Provence, the Solo Project Art Fair in Basel or the Centre pour l’Image Contemporaine in Geneva, and are represented by the 22,48 m² gallery in Paris.
Shu Lea Cheang (TW/FR) is a multimedia artist who constructs networked installations, social interfaces and film scenarios for public participation. BRANDON, a project exploring issues of gender fusion and techno-body, was an early web-based artwork commissioned by the Guggenheim Museum (NY) in 1998.
Dr Ian Cook (UK) is a cultural geographer of trade, researching the ways in which artists, filmmakers, activists and others try to encourage consumers to appreciate the work undertaken (and hardships often experienced) by the people who make the things we buy.
Paula Crutchlow (UK) is an artist who uses a mix of score, script, improvisation and structured participation to focus on boundaries between the public and private, issues surrounding the construction of ‘community’, and the politics of place.
Sarah T Gold (UK) is a designer working with emerging technologies, digital infrastructures and civic frameworks. Alternet is Sarah T Gold’s proposal for a civic network which extends from a desire to imagine, build and test future web infrastructure and digital tools for a more democratic society.
Dan Hassan (UK) is a computer engineer active in autonomous co-operatives over the last decade; in areas of economics (Robin Hood), housing (Radical Routes), migration (No Borders) and labour (Footprint Workers). He tweets as @dan_mi_sun
Jennifer Lyn Morone (US) founded Jennifer Lyn Morone™Inc in 2014. Since then, her mission is to establish the value of an individual in a data-driven economy and Late Capitalist society, while investigating and exposing issues of privacy, transparency, intellectual property, corporate governance, and the enabling political and legal systems.
Rhea Myers (UK) is an artist, writer and hacker based in Vancouver, Canada. His art comes from remix, hacking, and mass culture traditions, and has involved increasing amounts of computer code over time.
Brett Scott (UK) is campaigner, former broker, and the author of The Heretic’s Guide to Global Finance: Hacking the Future of Money (Pluto Press). He blogs at suitpossum.blogspot.com and tweets as @suitpossum
The Human Face of Cryptoeconomies is part of Art Data Money, Furtherfield’s new programme of art shows, labs and debates that invites people to discover new ways for cryptocurrencies and big data to benefit us all. It responds to the increasing polarisation of wealth and opportunity, aiming to build a set of actions to build resilience and sustain Furtherfield’s communities, platforms and economies.
About Furtherfield
Furtherfield was founded in 1997 by artists Marc Garrett and Ruth Catlow. Since then Furtherfield has created online and physical spaces and places for people to come together to address critical questions of art and technology on their own terms.
Furtherfield Gallery
McKenzie Pavilion
Finsbury Park, London, N4 2NQ
Visiting Information
Jonas Lund’s artistic practice revolves around the mechanisms that constitute contemporary art production, its market and the established ‘art worlds’. Using a wide variety of media, combining software-based works with performance, installation, video, photography and sculptures, he produces works that have an underlying foundation in writing code. By approaching art world systems from a programmatic point of view, the work engages through a criticality largely informed by algorithms and ‘big data’.
It’s been just over a year since Lund began his projects that attempt to redefine the commercial art world, because according to him, ‘the art market is, compared to other markets, largely unregulated, the sales are at the whim of collectors and the price points follows an odd combination of demand, supply and peer inspired hype’. Starting with The Paintshop.biz (2012) that showed the effects of collaborative efforts and ranking algorithms, the projects moved closer and closer to reveal the mechanisms that constitute contemporary art production, its market and the creation of an established ‘art world’. Its current peak was the solo exhibition The Fear Of Missing Out, presented at MAMA in Rotterdam.
Annet Dekker: The Fear Of Missing Out (FOMO) proposes that it is possible to be one step ahead of the art world by using well-crafted algorithms and computational logic. Can you explain how this works?
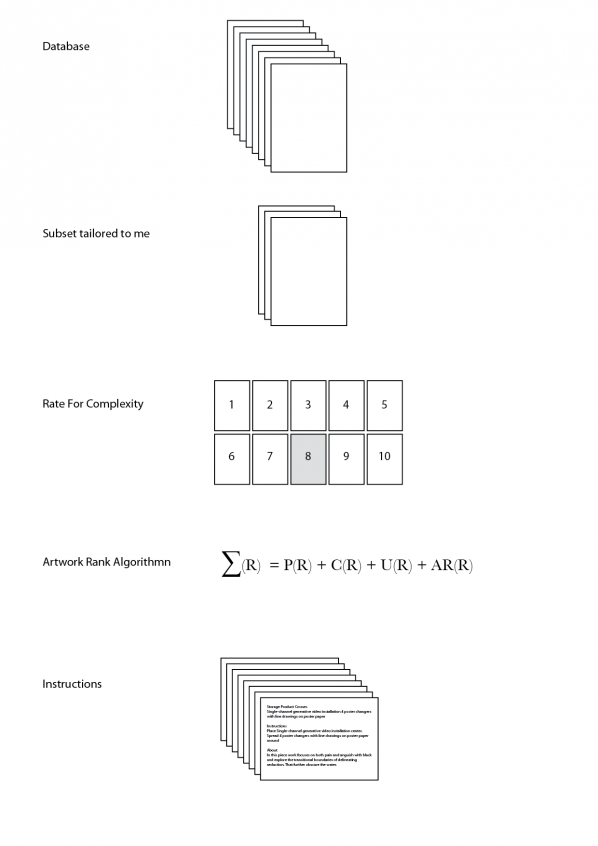
Jonas Lund The underlying motivation for the work is treating art worlds as networked based systems. The exhibition The Fear Of Missing Out spawned from my previous work The Top 100 Highest Ranked Curators In The World, for which I assembled a comprehensive database on the bigger parts of the art world using sources such as Artfacts, Mutaul Art, Artsy and e-flux. The database consists of artists, curators, exhibitions, galleries, institutions, art works and auction results. At the moment it has over four million rows of information. With this amount of information – ‘big data’ – the database has the potential to reveal the hidden and unfamiliar behaviour of the art world by exploring the art world as any other network of connected nodes, as a systemic solution to problematics of abstraction.


In The Top 100 Highest Ranked Curators In The World, first exhibited at Tent in Rotterdam, I wrote a curatorial ranking algorithm and used the database, to examine the underlying stratified network of artists and curators within art institutions and exhibition making: the algorithm determined who were among the most important and influential players in the art world. Presented as a photographic series of portraits, the work functions both as a summary of the increasingly important role of the curator in exhibition making, as an introduction to the larger art world database and as a guide for young up and coming artists for who to look out for at the openings.
Central to the art world network of different players lies arts production, this is where FOMO comes is. In FOMO, I used the same database as the basis for an algorithm that generated instructions for producing the most optimal artworks for the size of the Showroom MAMA exhibition space in Rotterdam while taking into account the allotted production budget. Prints, sculptures, installations and photographs were all produced at the whim of the given instructions. The algorithm used meta- data from over one hundred thousand art works and ranked them based on complexity. A subset of these art works were then used, based on the premise that a successful work of art has a high price, high aesthetic value but low production cost and complexity, to create instructions deciding title, material, dimensions, price, colour palette and position within the exhibition space.

Similar to how we’re becoming puppets to the big data social media companies, so I became a slave of the instructions and executed them without hesitation. FOMO proposes that it is possible to be one step ahead of the art world by using well-crafted algorithms and computational logic and questions notions of authenticity and authorship.
AD: To briefly go into one of the works, in an interview you mention Shield Whitechapel Isn’t Scoop – a rope stretched vertically from ceiling to floor and printed with red and yellow ink – as a ‘really great piece’, can you elaborate a little bit? Why is this to you a great piece, which, according to your statement in the same interview, you would not have made if it weren’t the outcome of your analysis?
JL: Coming from a ‘net art’ background, most of the previous works I have made can be simplified and summarised in a couple of sentences in how they work and operate. Obviously this doesn’t exclude further conversation or discourse, but I feel that there is a specificity of working and making with code that is pretty far from let’s say, abstract paintings. Since the execution of each piece is based on the instructions generated by the algorithm the results can be very surprising.
The rope piece to me was striking because as soon as I saw it in finished form, I was attracted to it, but I couldn’t directly explain why. Rather than just being a cold-hearted production assistant performing the instructions, the rope piece offered a surprise aha moment, where once it was finished I could see an array of possibilities and interpretations for the piece. Was the aha moment because of its aesthetic value or rather for the symbolism of climbing the rope higher, as a sort of contemporary art response to ‘We Started From The Bottom Now We’re Here’. My surprise and affection for the piece functions as a counterweight to the notion of objective cold big data. Sometimes you just have to trust the instructionally inspired artistic instinct and roll with it, so I guess in that way maybe now it is not that different from let’s say, abstract painting.

AD: I can imagine quite a few people would be interested in using this type of predictive computation. But since you’re basing yourself on existing data in what way does it predict the future, is it not more a confirmation of the present?
JL: One of the only ways we have in order to make predictions is by looking at the past. Through detecting certain patterns and movements it is possible to glean what will happen next. Very simplified, say that artist A was part of exhibition A at institution A working with curator A in 2012 and then in 2014 part of exhibition B at institution B working with curator A. Then say that artist B participates in exhibition B in 2013 working with curator A at institution A, based on this simplified pattern analysis, artist B would participate in exhibition C at institution B working with curator A. Simple right?
AD: In the press release it states that you worked closely with Showroom MAMA’s curator Gerben Willers. How did that relation give shape or influenced the outcome? And in what way has he, as a curator, influenced the project?
JL: We first started having a conversation about doing a show in the Summer of 2012, and for the following year we met up a couple of times and discussed what would be an interesting and fitting show for MAMA. In the beginning of 2013 I started working with art world databases, Gerben and I were making our own top lists and speculative exhibitions for the future. Indirectly, the conversations led to the FOMO exhibition. During the two production phases, Gerben and his team were immensely helpful in executing the instructions.
AD: Notion of authorship and originality have been contested over the years, and within digital and networked – especially open source – practices they underwent a real transformation in which it has been argued that authorship and originality still exist but are differently defined. How do see authorship and originality in relation to your work, i.e. where do they reside; is it the writing of the code, the translation of the results, the making and exhibiting of the works, or the documentation of them?
JL: I think it depends on what work we are discussing, but in relation to FOMO I see the whole piece, from start to finish as the residing place of the work. It is not the first time someone makes works based on instructions, for example Sol LeWitt, nor the first time someone uses optimisation ideas or ‘most cliché’ art works as a subject. However, this might be first time someone has done it in the way I did with FOMO, so the whole package becomes the piece. The database, the algorithm, the instructions, the execution, the production and the documentation and the presentation of the ideas. That is not to say I claim any type of ownership or copyright of these ideas or approaches, but maybe I should.
AD: Perhaps I can also rephrase my earlier question regarding the role of the curator: in what way do you think the ‘physical’ curator or artist influences the kind of artworks that come out? In other words, earlier instructions based artworks, like indeed Sol LeWitt’s artworks, were very calculated, there was little left to the imagination of the next ‘executor’. Looking into the future, what would be a remake of FOMO: would someone execute again the algorithms or try to remake the objects that you created (from the algorithm)?
JL: In the case with FOMO the instructions are not specific but rather points out materials, and how to roughly put it together by position and dimensions, so most of the work is left up to the executor of said instructions. It would not make any sense to re-use these instructions as they were specifically tailored towards me exhibiting at Showroom MAMA in September/October 2013, so in contrast to LeWitt’s instructions, what is left and can travel on, besides the executions, is the way the instructions were constructed by the algorithm.
AD: Your project could easily be discarded as confirming instead of critiquing the established art world – this is reinforced since you recently attached yourself to a commercial gallery. In what way is a political statement important to you, or not? And how is that (or not) manifested most prominently?
JL: I don’t think the critique of the art world is necessarily coming from me. It seems like that is how what I’m doing is naturally interpreted. I’m showing correlations between materials and people, I’ve never made any statement about why those correlations exist or judging the fact that those correlations exist at all. I recently tweeted, ‘There are three types of lies: lies, damned lies and Big Data’, anachronistically paraphrasing Mark Twain’s distrust for the establishment and the reliance on numbers for making informed decisions (my addition to his quote). Big data, algorithms, quantification, optimisation… It is one way of looking at things and people; right now it seems to be the dominant way people want to look at the world. When you see that something deemed so mysterious as the art world or art in general has some type of structural logic or pattern behind it, any critical person would wonder about the causality of that structure, I guess that is why it is naturally interpreted as an institutional critique. So, by exploring the art world, the market and art production through the lens of algorithms and big data I aim to question the way we operate within these systems and what effects and affects this has on art, and perhaps even propose a better system.
AD: How did people react to the project? What (if any) reactions did you receive from the traditional artworld on the project?
JL: Most interesting reactions usually take place on the comment sections of a couple of websites that published the piece, in particular Huffington Post’s article ‘Controversial New Project Uses Algorithm To Predict Art’. Some of my favourite responses are:
‘i guess my tax dollars are going to pay this persons living wages?’
‘Pure B.S. ……..when everything is art then there is no art’
‘As an artist – I have no words for this.’
‘Sounds like a great way to sacrifice your integrity.’
‘Wanna bet this genius is under 30 and has never heard of algorithmic composition or applying stochastic techniques to art production?’
‘Or, for a fun change of pace, you could try doing something because you have a real talent for it, on your own.’
AD: Even though the project is very computational driven, as you explain the human aspects is just as important. A relation to performance art seems obvious, something that is also present in some of your other works most notably Selfsurfing (2012) where people over a 24 hour period could watch you browsing the World Wide Web, and Public Access Me (2013), an extension of Selfsurfing where people when logged in could see all your online ‘traffic’. A project that recalls earlier projects like Eva & Franco Mattes’ Life Sharing (2000). In what way does your project add to this and/or other examples from the past?
JL: Web technology changes rapidly and what is possible today wasn’t possible last year and while most art forms are rather static and change slowly, net art in particular has a context that’s changing on a weekly basis, whether there is a new service popping up changing how we communicate with each other or a revaluation that the NSA or GCHQ has been listening in on even more facets of our personal lives. As the web changes, we change how we relate to it and operate within it. Public Access Me and Selfsufing are looking at a very specific place within our browsing behaviour and breaks out of the predefined format that has been made up for us.
There are many works within this category of privacy sharing, from Kyle McDonalds’ live tweeter, to Johannes P Osterhoff’s iPhone Live and Eva & Franco Mattes’ earlier work as you mentioned. While I cannot speak for the others, I interpret it as an exploration of a similar idea where you open up a private part of your daily routine to re-evaluate what is private, what privacy means, how we are effected by surrendering it and maybe even simultaneously trying to retain or maintain some sense of intimacy. Post-Snowden, I think this is something we will see a lot more of in various forms.
AD: Is your new piece Disassociated Press, following the 1970s algorithm that generated text based on existing texts, a next step in this process? Why is this specific algorithm of the 70s important now?

JL: Central to the art world lies e-flux, the hugely popular art newsletter where a post can cost up to one thousand dollars. While spending your institution’s money you better sound really smart and using a highly complicated language helps. Through the course of thousands of press releases, exhibition descriptions, artist proposals and curatorial statements a typical art language has emerged. This language functions as a way to keep outsiders out, but also as a justification for everything that is art.
Disassociated Press is partly using the Dissociated Press algorithm developed in 1972, first associated with the Emacs implementation. By choosing a n-gram of predefined length and consequently looking for occurrences of these words within the n-gram in a body of text, new text is generated that at first sight seems to belong together but doesn’t really convey a message beyond its own creation. It is a summary of the current situation of press releases in the international English art language perhaps, as a press release in its purest form. So, Disassociated Press creates new press releases to highlight the absurdity in how we talk and write about art. If a scrambled press release sounds just like normal art talk then clearly something is wrong, right?
Jonas Lund’s “The Fear Of Missing Out” (2013) is a series of gallery art objects made by the artist following the instructions of a piece of software they have written. It has gained attention following a Huffington Post article titled “Controversial New Project Uses Algorithm To Predict Art “.
Art fabricated by an artist following a computer-generated specification is nothing new. Prior to modern 2D and 3D printing techniques, transcribing a computer generated design into paint or metal by hand was the only way to present artworks that pen plotters or CNC mills couldn’t capture. But a Tamagotchi-gamer or Amazon Mechanical Turk-style human servicing of machine agency where a program dictates the conception of an artwork for a human artist to realize also has a history. The principles involved go back even further to the use of games of chance and other automatic techniques in Dada and Surrealism.

What is novel about The Fear Of Missing Out is that the program dictating the artworks is doing so based on a database derived from data about artworks, art galleries, and art sales. This is the aesthetic of “Big Data“, although is not a big dataset by the definition of the term. Its source, and the database, are not publicly available but assuming it functions as specified the description of the program in the Huffington Post article about it is complete enough that we could re-implement it. To do so we would scrape Art Sales Index and/or Artsy and pull out keywords from entries to populate a database keyed on artist, gallery and sales details. Then we would generate text from those details that match a desired set of criteria such as gallery size and desired price of artwork.
What’s interesting about the text described in the Huffington Post article is that it’s imperative and specific: “place the seven minute fifty second video loop in the coconut soap”. How did the instruction get generated? Descriptions of artworks in artworld data sites describe their appearance and occasionally their construction, not how to assemble them. If it’s a grammatical transformation of scraped description text that fits the description of the project, but if it’s hand assembled that’s not just a database that has been “scraped into existence”. How did the length of time get generated? If there’s a module to generate durations that doesn’t fit the description of the project, but if it’s a reference to an existing 7.50 video it does.
The pleasant surprises in the output that the artist says they would not have thought of but find inspiring are explained by Edward de Bono-style creativity theory. And contemporary art oeuvres tend to be materially random enough that the randomness of the works produced looks like moments in such an oeuvre. Where the production differs both from corporate big data approaches and contemporary artist-as-brand approaches is that production is not outsourced. Lund makes the art that they use data to specify.

Later, the Huffington Post article mentions the difficulty of targeting specific artists. A Hirst artwork specification generator would be easy enough to create for artworks that resemble his existing oeuvre. Text generators powered by markov chains were used as a tool for parodying Usenet trolls, and their strength lies in the predictability of the obsessed. Likewise postmodern buzzword generators and paper title generators parody the idees fixes of humanities culture.
The output of such systems resembles the examples that they are derived from. Pivoting to a new stage in an artist’s career is something that would require a different approach. It’s possible to move, logically, to conceptual opposites using Douglas Hofstadter’s approaches. In the case of Hirst, cheap and common everyday materials (office equipment) become expensive and exclusive ones (diamonds) and the animal remains become human ones.

This principle reaches its cliometric zenith in Colin Martindale’s book “The Clockwork Muse: The Predictability of Artistic Change”. It’s tempting to dismiss the idea that artistic change occurs in regular cycles as the aesthetic equivalent of Kondratieff Waves as Krondatieff Waves are dismissed by mainstream economics. But proponents of both theories claim empirical backing for their observations.
In contrast to The Fear Of Missing Out’s private database and the proprietary APIs of art market sites there is a move towards Free (as in freedom) or Open Data for art institutions. The Europeana project to release metadata for European cultural collections as linked open data has successfully released data from over 2000 institutions across the EU. The Getty Foundation has put British institutions that jealously guard their nebulously copyrighted photographs of old art to shame by releasing almost 5000 images freely. And most recently the Tate gallery in the UK has released its collection metadata under the free (as in freedom) CC0 license.

Shardcore’s “Machine Imagined Artworks” (2013) uses the Tate collection metadata to make descriptions of possible artworks. Compared to the data-driven approach of The Fear Of Missing Out, Machine Imagined Artworks is a more traditional generative program using unconstrained randomness to choose its materials from within the constrained conceptual space of the Tate data’s material and subjects ontologies.
Randomness is ubiquitous but often frowned upon in generative art circles. It gives good results but lacks intention or direction. Finding more complex choice methods is often a matter of rapidly diminishing returns, though. And Machine Imagined Artworks makes the status of each generated piece as a set of co-ordinates in conceptual space explicit by numbering it as one of the 88,577,208,667,721,179,117,706,090,119,168 possible artworks that can be generated from the Tate data.
Machine Imagined Artworks describes the formal, intentional and critical schema of an artwork. This reflects the demands placed on contemporary art and artists to fit the ideology both of the artworld and of academia as captured in the structure of the Tate’s metadata. It makes a complete description of an artwork under such a view. The extent to which such a description seems incomplete is the extent to which it is critical of that view.
We could use the output of Machine Imagined Artworks to choose 3D models from Thingiverse to mash-up. Automating this would remove human artists from the creative process, allowing the machines to take their jobs as well. The creepy fetishization of art objects as quasi-subjects rather than human communication falls apart here. There is no there there in such a project, no agency for the producer or the artwork to have. It’s the uncanny of the new aesthetic.
Software that directs or displaces an artist operationalises (if we must) their skills or (more realistically) replaces their labour, making them partially or wholly redundant. Dealing in this software while maintaining a position as an artist represents this crisis but does not embody it as the artist is still employed as an artist. Even when the robots take artists jobs, art critics will still have work to do, unless software can replace them as well.

There is a web site of markov chain-generated texts in the style of the Art & Language collective’s critical writing at http://artandlanguage.co.uk/, presumably as a parody of their distinctive verbal style. Art & Language’s painting “Gustave Courbet’s ‘Burial at Ornans’ Expressing…” (1981) illustrates some of the problems that arbitrary assemblage of material and conceptual materials cause and the limitations both of artistic intent and critical knowledge. The markov chain-written texts in their style suffer from the weakness of such approaches. Meaning and syntax evaporate as you read past the first few words. The critic still has a job.

Or do they? Algorithmic criticism also has a history that goes back several decades, to Gips and Stiny’s book “Algorithmic Aesthetics” (1978). It is currently a hot topic in the Digital Humanities, for example with Stephen Ramsay’s book “Reading Machines: Toward an Algorithmic Criticism” (2011). The achievements covered by each book are modest, but demonstrate the possibility of algorithmic critique. The problem with algorithmic critique is that it may not share our aesthetics, as the ST5 antenna shows.

Shardcore’s “Cut Up Magazine” (2012) is a generative critic that uses a similar strategy to “The Fear Of Missing Out”. It assembles reviews from snippets of a database of existing reviews using scraped human generated data about the band such as their name, genre, and most popular songs. Generating the language of critique in this way is subtly critical of its status and effect for both its producers and consumers. The language of critique is predictable, and the authority granted to critics by their audience accords a certain status to that language. Taken from and returned to fanzines, Cut Up Magazine makes the relationship between the truth of critique, its form, and its status visible to critique.
We can use The Fear Of Missing Out-style big data approaches to create critique that has a stronger semantic relationship to its subject matter. First we scrape an art review blog to populate a database of text and images. Next we train an image classifier (a piece of software that tells you whether, for example, an image contains a Soviet tank or a cancer cell or not) and a text search engine on this database. Then we use sentiment analysis software (the kind of system that tells airlines whether tweets about them are broadly positive or negative) to generate a score of one to five stars for each review and store this in the database.
We can now use this database to find the artworks that are most similar in appearance and description to those that have already been reviewed. This allows us to generate a critical comment about them and assign them a score. Given publishing fashion we can then make a list of the results. The machines can take the critic’s job as well, as I have previously argued.
What pieces like The Fear Of Missing Out and Machine Imagined Artworks make visible is an aspect of How Things Are Done Now and how this affects everyone, regardless of the nature of their work. This is “big data being used to guide the organization”. To regard such projects simply as parody or as play acting is to take a literary approach to art. But art doesn’t need to resolve such ontological questions in order to function, and may provide stronger affordances to thought if it doesn’t. What’s interesting is both how much such an approach misses and how much it does capture. As ever, art both reveals and symbolically resolves the aporia of (in this case the Californian) ideology.
The text of this review is licenced under the Creative Commons BY-SA 3.0 Licence.
