

“AI just 3D printed a brand-new Rembrandt, and it’s shockingly good” reads the title of a PC World article in April 2016. Advertising firm J. Walter Thompson unveiled a 3D printed painting called “The Next Rembrandt”, based on 346 paintings of the old master. Not just PC World, many more articles touted similar titles, presenting the painting to the public as if it were made by a computer, a 3D printer, Artificial Intelligence and deep learning. It is clear though that the programmers who worked on the project are not computers, and neither are the people who tagged the 346 Rembrandt paintings by hand. The painting was made by a team of programmers and researchers, and it took them 18 months to do so.
A very successful feat of advertising, and a great example of how eager we are to attribute human qualities to computers and see data as the magic powder bringing life to humanity’s most confusing tool. Data is the new black… it can touch our soul according to a Microsoft spokesperson on the website of the Next Rembrandt: “Data is used by many people today to help them be more efficient and knowledgeable about their daily work, and about the decisions they need to make. But in this project it’s also used to make life itself more beautiful. It really touches the human soul.” (Ron Augustus, Microsoft). We have elevated data to divine standards and have developed a tendency to confuse tools with their creators in the process. Nobody in the 17th Century would have dreamed of claiming a brush and some paint created The Night Watch, or that it’s a good idea to spend 18 months on one painting.
The anthropomorphisation of computers was researched in depth by Reeves and Nass in The Media Equation (1996). They show through multiple experiments how people treat computers, television, and new media like real people and places. On the back of the book, Bill Gates says Nass and Reeves show us some “amazing things”. And he was right. Even though test subjects were completely unaware of it, they responded to computers as they would to people, by being polite, cooperative, attributing personality characteristics such as aggressiveness, humour, expertise, and even gender. If only Microsoft would use this knowledge to improve the way people interact with their products, instead of using it for advertising campaigns promoting a belief in the magic powers of computers and data. Or… oh wait… This belief, combined with the anthropomorphising of computers, profoundly alters the way people interact with machines and makes it much more likely that users will accept and adapt to the limitations and demands of technology, instead of demanding technology should adapt to them.
Strangely enough, the anthropomorphising of computers goes hand in hand with attributing authority, objectivity, even superiority to computer output by obfuscating the human hand in its generation. It seems paradoxical to attribute human qualities to something, while at the same time considering it to be more objective than humans. How can these two beliefs exist side by side? We are easily fooled, ask any magician. As long as our attention is distracted, steered, you can hide things in plain sight. We haven’t been too bothered with this paradox in the past. The obfuscation of a human hand in the generation of messages that require an objective or authoritative feel is very old. As a species, we’ve always turned to godly or mythical agents, in order to make sense of what we did not understand, to seek counsel. We asked higher powers to guide us. These higher powers rarely spoke to us directly. Usually messages were mediated by humans: priestesses, shamans or oracles. These mediations were validated as objective and true transmissions through a formalisation of the process in ritual, and later institutionalised as religion, obfuscating the human hand in the generation of these messages. Although disputed, it is commonly believed that the Delphic oracle delivered messages from her god Apollo in a state of trance, induced by intoxicating vapours arising from the chasm over which she was seated. Possessed by her god the oracle spoke, ecstatically and spontaneously. Priests of the temple translated her words into the prophecies the seekers of advice were sent home with. Apollo had spoken.

Nowadays we turn to data for advice. The oracle of big data[1] functions in a similar way to the oracle of Delphi. Algorithms programmed by humans are fed data and consequently spit out numbers that are then translated and interpreted by researchers into the prophecies the seekers of advice are sent home with. The bigger the data set, the more accurate the results. Data has spoken. We are brought closer to the truth, to reality as it is, unmediated by us subjective, biased and error-prone humans. We seek guidance, just like our ancestors, hoping we can steer events in our favour. Because of this point of departure, very strong emotions are attached to big data analysis, feelings of great hope and intense fear. Visions of utopia, the hope that it will create new insights into climate change and accurate predictions of terrorist attacks, protecting us from great disaster. At the same time there are visions of dystopia, of a society where privacy invasion is business as usual, and through this invasion an ever increasing grip on people through state and corporate control, both directly and through unseen manipulation.
Let’s take a closer look at big data utopia, where the analysis of data will protect us from harm. This ideology is fed by fear and has driven states and corporations alike to gather data like there is no tomorrow or right to privacy, at once linking it very tightly to big data dystopia. What is striking is that the fear of terrorist attacks has led to lots of data gathering, the introduction of new laws and military action on the part of governments, yet the fear of climate change has led to only very moderate activity. Yet the impact of the latter is likely to have more far reaching consequences on humanity’s ability to survive. In any case, the idea of being able to predict disaster is a tricky one. In the case of global warming, we can see it coming and aggravating because it is already taking place. But other disasters are hard to predict and can only be explained in retrospect. In Antifragility, Nicolas Taleb (2013, pp.92-93), inspired by a metaphor of Bertrand Russell, quite brilliantly explains the tendency to mistake absence of evidence for evidence of absence with a story about turkeys. Turkeys are fed for a thousand days by a butcher, leading them to believe, backed up by statistical evidence, that butchers love turkeys. Right when the turkey is most convinced that butchers love turkeys, when it is well fed and everything is quiet and predictable, the butcher surprises the turkey which has to drastically revise its beliefs.
An only slightly more subtle version of big data utopia is a utopia where data can speak, brings us closer to reality as it is, where we can safely forget theory and ideas and other messy subjective human influences through crunching enormous amounts of numbers.
“This is a world where massive amounts of data and applied mathematics replace every other tool that might be brought to bear. Out with every theory of human behaviour, from linguistics to sociology. Forget taxonomy, ontology, and psychology. Who knows why people do what they do? The point is they do it, and we can track and measure it with unprecedented fidelity. With enough data, the numbers speak for themselves.” (Anderson, 2008)
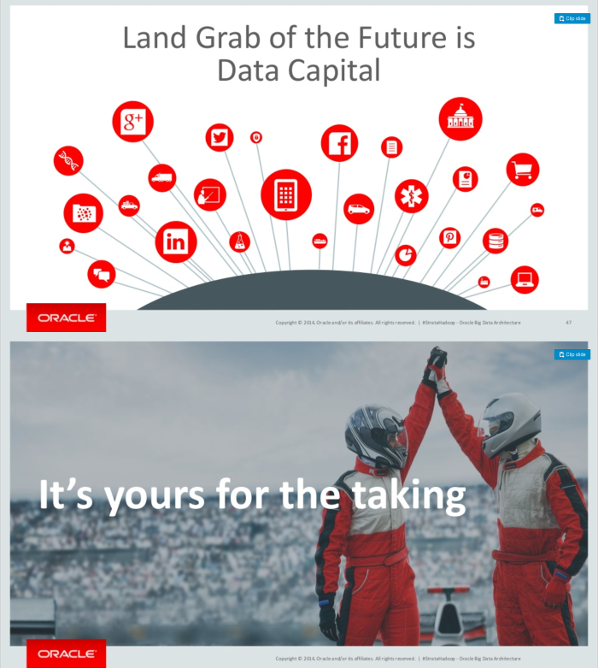
Using this rhetoric, there is no more need for models or hypotheses, correlation is enough. Just throw in the numbers and the algorithms will spit out patterns that traditional scientific methods were unable to bring to light. This promise sells well and companies providing data analysis and storage services promote it with great enthusiasm, as demonstrated by two slides in an Oracle presentation at Strata 2015: “Data Capital is the land grab of the future” and “It’s yours for the taking” (Pollock, 2015).
Can numbers really speak for themselves? When taking a closer look, a lot of assumptions come to light, constructing the myth of the oracle. Harford (2014) describes these assumptions as four articles of faith. The first is the belief in uncanny accuracy. This belief focuses all attention on the cases where data analysis made a correct prediction, while ignoring all false positive findings. Being right one out of ten times may still be highly profitable for some business applications, but uncannily accurate it is not. The second article is the belief that not causation, but correlation matters. The biggest issue with this belief is that if you don’t understand why things correlate, you have no idea why they might stop correlating either, making predictions very fragile in an ever changing world. Third is the faith in massive data sets being immune to sampling bias, because there is no selection taking place. Yet found data contains a lot of bias, as for example not everyone has a smartphone, and not everyone is on Twitter. Last but not least, the fourth belief, that numbers can speak for themselves… is hard to cling to when spurious correlations create so much noise, it’s hard to filter out the real discoveries. Taleb (2013, p.418) points to the enormous amount of cherry-picking done in big data research. There are way too many variables in modern life, making spurious relations grow at a much faster pace than real information.
As a rather poetic example, Leinweber (2007) demonstrated that data mining techniques could show a strong but spurious correlation between the changes in the S&P 500 stock index and butter production in Bangladesh. There is more to meaningful data analysis than finding statistical patterns, which show correlation rather than causation. Boyd and Crawford describe the beliefs attached to big data as a mythology, “the widespread belief that large data sets offer a higher form of intelligence and knowledge that can generate insights that were previously impossible, with the aura of truth, objectivity, and accuracy” (Boyd and Crawford, 2012). The belief in this oracle has quite far reaching implications. For one, it dehumanises humans by asserting that human involvement through hypotheses and interpretation, is unreliable, and only by removing humans from the equation can we finally see the world as it is. While putting humans and human thought on the sideline, it obfuscates the human hand in the generation of its messages and anthropomorphises the computer by claiming it is able to analyse, draw conclusions, even speak to us. The practical consequence of this dynamic is that it is no longer possible to argue with the outcome of big data analysis. This becomes painful when you find yourself in the wrong category of a social sorting algorithm guiding real world decisions on insurance, mortgage, work, border checks, scholarships and so on. Exclusion from certain privileges is only the most optimistic scenario, more dark ones involve basic human rights.
The deconstruction of this myth was attempted as early as 1984. In “A Spreadsheet Way of Knowledge”, Stephen Levy describes how the authoritative look of a spreadsheet, and the fact that it was done by a computer, has a strong persuasive effect on people, leading to acceptance of the proposed model of reality as gospel. Levy points out that all the benefits of using spreadsheets are meaningless if the metaphor is taken too seriously. He concludes with a statement completely opposite to what Anderson will state 24 years later: “Fortunately, few would argue that all relations between people can be quantified and manipulated by formulas. Of human behaviour, no faultless assumptions – and so no perfect model — can be made”. A lot has changed in 24 years. Still back in the eighties, Theodore Roszak describes the subjective core of software beautifully: “Computers, as the experts continually remind us, are nothing more than their programs make them. But as the sentiments above should make clear, the programs may have a program hidden within them, an agenda of values that counts for more than all the interactive virtues and graphic tricks of the technology. The essence of the machine is its software, but the essence of the software is its philosophy” (Roszak, 1986). This essence, sadly, is often forgotten, and outcomes of data analysis therefore misinterpreted. In order to correctly assess the outcomes of data analysis it is essential to acknowledge that interpretation is at the heart of the process, and assumptions, bias and limitations are undeniable parts of it.
In order to better understand the widespread belief in the myth of big data, it is important to look at the shift in the meaning of the word information (Roszak, 1986). In the 1950s, with the advent of cybernetics, the study of feedback in self-regulating closed systems, information transformed from short statement of fact to the means to control a system, any system, be it mechanical, physical, biological, cognitive or social (Wiener, 1950). In the 1960s artificial intelligence researchers started viewing both computers and humans as information processing systems (Weizenbaum, p.169). In the 1970s it was granted an even more powerful status, that of commodity. The information economy was born and promoted with great enthusiasm in the 1980s.
“Reading Naisbitt and Toffler is like a fast jog down a world’s Fair Midway. We might almost believe, from their simplistic formulation of the information economy, that we will soon be living on a diet of floppy disks and walking streets paved with microchips. Seemingly, there are no longer any fields to till, any ores to mine, any heavy industrial goods to manufacture; at most these continuing necessities of life are mentioned in passing and then lost in the sizzle of pure electronic energy somehow meeting all human needs painlessly and instantaneously.” (Roszak, 1986, p. 22).
Nowadays not only corporations and governments, but individuals have become information hungry. What started as a slightly awkward hobby in the 80s, the quantified self has now become mainstream with people self monitoring anything from sleep to eating habits, from sport activities to mood using smartphones and smartwatches with build-in sensors, uploading intimate details such as heart-rate, sleep patterns and whereabouts to corporate servers in order to improve their performance.
Even with this change in the way we view information in mind, it is difficult to believe we cannot see through the myth. How did it become plausible to transpose cybernetic thinking from feedback in self-regulating closed systems to society and even to human beings? It is quite a leap, but we somehow took it. Do humans have anything in common with such systems? Weizenbaum (1976) explains our view of man as machine through our strong emotional ties to computers, through the internalisation of aspects of computers in order to operate them, in the form of kinaesthetic and perceptual habits. He describes how in that sense, man’s instruments become part of him and alter the nature of his relationship to himself. In The Empty Brain (2016) research psychologist Robert Epstein writes about the idea that we nowadays tend to view ourselves as information processors, but points out there is a very essential difference between us and computers: humans have no physical representations of the world in their brains. Our memory and that of a computer have nothing in common, we do not store, retrieve and process information and we are not guided by algorithms.
Epstein refers to George Zarkadakis’ book In Our Own Image (2015), where he describes six different metaphors people have employed over the past 2,000 years to try to explain human intelligence. In the earliest one, eventually preserved in the Bible, humans were formed from clay or dirt, which an intelligent god then infused with its spirit. This spirit somehow provided our intelligence. The invention of hydraulic engineering in the 3rd century BC led to the popularity of a hydraulic model of human intelligence, the idea that the flow of different fluids in the body – the ‘humours’ – accounted for both our physical and mental functioning. By the 1500s, automata powered by springs and gears had been devised, eventually inspiring leading thinkers such as René Descartes to assert that humans are complex machines. By the 1700s, discoveries about electricity and chemistry led to new theories of human intelligence – again, largely metaphorical in nature. In the mid-1800s, inspired by recent advances in communications, the German physicist Hermann von Helmholtz compared the brain to a telegraph. Predictably, just a few years after the dawn of computer technology in the 1940s, the brain was said to operate like a computer, with the role of physical hardware played by the brain itself and our thoughts serving as software.
This explanation of human intelligence, the information processing metaphor, has infused our thinking over the past 75 years. Even though our brains are wet and warm, obviously an inseparable part of our bodies, and using not only electrical impulses but also neurotransmitters, blood, hormones and more, nowadays it is not uncommon to think of neurons as ‘processing units’, synapses as ‘circuitry’, ‘processing’ sensory ‘input’, creating behavioural ‘outputs’. The use of metaphors to describe science to laymen also led to the idea that we are ‘programmed’ through the ‘code’ contained in our DNA. Besides leading to the question of who the programmer is, these metaphors make it hard to investigate the nature of our intelligence and the nature of our machines with an open mind. They make it hard to distinguish the human hand in computers, from the characteristics of the machine itself, anthropomorphising the machine, while at the same time dehumanising ourselves. For instance, Alan Turing’s test to prove if a computer could be regarded as thinking, now is popularly seen as a test that proves if a computer is thinking. Only in horror movies would a puppeteer start to perceive his puppet as an autonomous and conscious entity. The Turing test only shows whether or not a computer can be perceived of as thinking by a human. That is why Turing called it the imitation game. “The Turing Test is not a definition of thinking, but an admission of ignorance — an admission that it is impossible to ever empirically verify the consciousness of any being but yourself.” (Schulman, 2009). What a critical examination of the IP metaphor makes clear, is that in an attempt to make sense of something we don’t understand, we’ve invented a way of speaking about ourselves and our technology that obscures instead of clarifies both our nature and that of our machines.
Why dehumanize and marginalize ourselves through the paradox of viewing ourselves as flawed, wanting a higher form of intelligence to guide us, envisioning superhuman powers in a machine created by us, filled with programs written by us, giving us nothing but numbers that need interpretation by us, obfuscating our own role in the process yet viewing the outcome as authoritative and superior. A magician cannot trick himself. Once revealed, never concealed. Yet we manage to fall for a self created illusion time and time again. We fall for it because we want to believe. We joined the church of big data out of fear, in the hope it would protect us from harm by making the world predictable and controllable. With the sword of Damocles hanging over our heads, global warming setting in motion a chain of catastrophes, threatening our survival, facing the inevitable death of capitalism’s myth of eternal growth as earth’s resources run out, we need a way out. Since changing light bulbs didn’t do the trick, and changing the way society is run seems too complicated, the promise of a technological solution inspires great hope. Really smart scientists, with the help of massive data sets and ridiculously clever AI will suddenly find the answer. In ten years time we’ll laugh at the way we panicked about global warming, safely aboard our CO2 vacuum cleaners orbiting a temporarily abandoned planet Earth.
Theinformation processing metaphor got us completely hooked on gathering data. We are after all information processors. The more data at our fingertips, the more powerful we become. Once we have enough data, we will finally be in control, able to predict formerly unforeseen events, able to steer the outcome of any process because for the first time in history we’ll understand the world as it really is. False hope. Taken to itsextreme, the metaphor leads to the belief that human consciousness, being so similar to computer software, can be transferred to a computer.
“One prediction – made by the futurist Kurzweil, the physicist Stephen Hawking and the neuroscientist Randal Koene, among others – is that, because human consciousness is supposedly like computer software, it will soon be possible to download human minds to a computer, in the circuits of which we will become immensely powerful intellectually and, quite possibly, immortal.” (Epstein, 2016).
False hope. Another example is the project Alliance to Rescue Civilization (ARC), by scientists E. Burrows and Robert Shapiro. It is a project that aims to back up human civilization in a lunar facility. The project artificially separates the “hardware” of the planet with its oceans and soils, and the “data” of human civilization (Bennan, 2016). Even thoughseeing the need to store things off-planet conveys aless than optimisticoutlook on the future, the project gives the false impression that technology can separate us from earth. A project pushing this separation to its extreme is Elon Musk’s SpaceX plan to colonize Mars, announced in June 2016, and gaining momentum with his presentation at the 67th International Astronautical Congress in Guadalajara, September 27th. The goal of the presentation was to make living on Mars seem possible within our lifetime. Possible, and fun.
“It would be quite fun because you have gravity, which is about 37% that of Earth, so you’d be able to lift heavy things and bound around and have a lot of fun.” (Musk, 2016).
We are inseparable from the world we live in. An artificial separation from earth, which we are part of and on which our existence depends, will only lead to a more casual attitude towards the destruction of its ecosystems. We‘ll never be immortal, downloadable or rescued from a lunar facility in the form of a back up. Living on Mars is not only completely impossible at this moment, nothing guarantees it will bein the future. Even if it were possible, and you would be one of the select few that could afford to go, you’d spend your remaining days isolated on a life-less, desolate planet, chronically sleep deprived, with a high risk of cancer, a bloated head, the bone density and muscle mass worse than that of a 120 year old, due to the small amount of gravity and high amount of radiation (Chang, 2014).Just like faster and more precise calculations regarding the position of planets in our solar system will not make astrology more accurate in predicting the future, faster machines, more compact forms of data storage and larger data setswill not make us able to predict and control the future. Technological advances will not transform our species from a slowly evolving one, into one that can adapt to extreme changes in our environmentinstantly, as we would need to in the case of a rapidly changing climate or a move to another planet.
These are the more extreme examples, that are interesting because they make the escapist attitude to our situation so painfully clear. Yet the more widely accepted beliefs are just as damaging. The belief that with so much data at our fingertips, we’ll make amazing new discoveries that will safe us just in time, leads to hope that distracts us from the real issues that threaten us. There are 7.4 billion of us. The earth’s resources are running out. Climate change will set in motion a chain of events we cannot predict precisely but dramatic sea level rises and mass extinction will be part of it without doubt. We cannot all Houdini out of this one, no matter how tech savvy we might become in the next decades. Hope is essential, but a false sense of safety paralyses us and we need to start acting. In an attempt to understand the world, to become less fragile, in the most rational and scientifically sound way we could think of, we’ve started anthropomorphising machines and dehumanising ourselves. This has, besides inspiring a great number of Hollywood productions, created a massive blind spot and left us paralysed. While we are bravely filling up the world’s hard disks, we ignore our biggest weakness: this planet we are on, it’s irreplaceable and our existence on it only possible under certain conditions. Our habits, our quest to become more productive, more efficient, more safe, less mortal, more superhuman, actually endangers us as a species… With technology there to save us, there is no urgency to act. Time to dispel the myth, to exit the church of big data and start acting in our best interest, as a species, not as isolated packages of selfish genes organized as information processors ready to be swooshed off the planet in a singularity style rapture.

